
Founder of LearnDataSci

CS & Engineering Post Graduate
Sentiment Analysis on Reddit News Headlines with Python’s Natural Language Toolkit (NLTK)
Let's use the Reddit API to grab news headlines and perform Sentiment Analysis
LearnDataSci is reader-supported. When you purchase through links on our site, earned commissions help support our team of writers, researchers, and designers at no extra cost to you.
You should already know:
- Python fundamentals
- Basic machine learning concepts
Learn both interactively through dataquest.io
In the last post, K-Means Clustering with Python, we just grabbed some precompiled data, but for this post, I wanted to get deeper into actually getting some live data.
Using the Reddit API we can get thousands of headlines from various news subreddits and start to have some fun with Sentiment Analysis.
We are going to use NLTK's vader analyzer, which computationally identifies and categorizes text into three sentiments: positive, negative, or neutral.
Article Resources
- Notebook: GitHub
- Libraries: pandas, numpy, nltk, matplotlib, seaborn
Getting Started
First, some imports:
from IPython import display
import math
from pprint import pprint
import pandas as pd
import numpy as np
import nltk
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(style='darkgrid', context='talk', palette='Dark2')These imports will be cleared up once they are used. The three that are worth mentioning now are pprint, which lets us "pretty-print" JSON and lists, seaborn, which will add styles to the matplotlib graphs, and iPython's display module, which will let us control the clearing of printed output inside loops. More on these below.
NLTK
Before we get started with gathering the data, you will need to install the Natural Language Toolkit (NLTK) python package. To see how to install NLTK, you can go here: http://www.nltk.org/install.html. You'll need to open Python command line and run nltk.download() to grab NLTK's databases.
Reddit API via PRAW
For this tutorial, we'll be using a Reddit API wrapper, called `praw`, to loop through the /r/politics subreddit headlines.
To get started with `praw`, you will need to create a Reddit app and obtain your Client ID and Client Secret.
Making a Reddit app
Simply follow these steps:
- Log into your account
- Navigate to https://www.reddit.com/prefs/apps/
- Click on the button that says "are you a developer? create an app..."
- Enter a name (username works)
- Select "script"
- Use http://localhost:8080 as a redirect URI
- Once you click "create app", you'll see where your Client ID and Client Secret are.
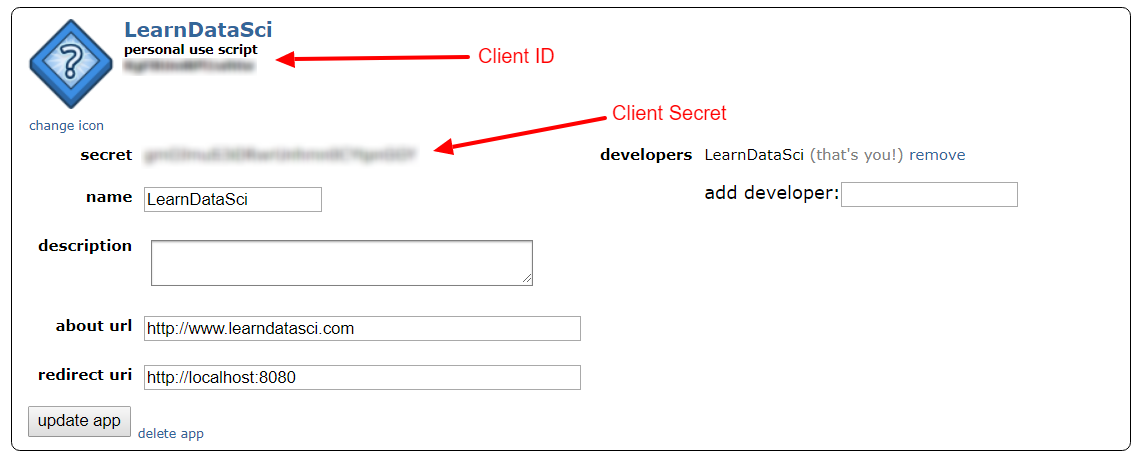
Now to get started with praw, we need to first create a Reddit client.
Just replace your details in the following lines (without carets < >):
import praw
reddit = praw.Reddit(client_id='<your_client_id>',
client_secret='<your_client_secret>',
user_agent='<your_user_name>')Let's define a set for our headlines so we don't get duplicates when running multiple times:
headlines = set()Now, we can iterate through the /r/politics subreddit using the API client:
for submission in reddit.subreddit('politics').new(limit=None):
headlines.add(submission.title)
display.clear_output()
print(len(headlines))965We're iterating over the "new" posts in /r/politics, and by setting the limit to None we can get up to 1000 headlines. This time we only received 965 headlines.
PRAW does a lot of work for us. It lets us use a really simple interface while it handles a lot of tasks in the background, like rate limiting and organizing the JSON responses.
Unfortunately, without some more advanced tricks we can't go past 1000 results since Reddit cuts off at that point. We can run this loop multiple times and keep adding new headlines to our set, or we can implement a streaming version. There's also a way to take advantage of Reddit's search with time parameters, but let's move on to the Sentiment Analysis of our headlines for now.
Labeling our Data
NLTK’s built-in Vader Sentiment Analyzer will simply rank a piece of text as positive, negative or neutral using a lexicon of positive and negative words.
We can utilize this tool by first creating a Sentiment Intensity Analyzer (SIA) to categorize our headlines, then we'll use the polarity_scores method to get the sentiment.
We'll append each sentiment dictionary to a results list, which we'll transform into a dataframe:
from nltk.sentiment.vader import SentimentIntensityAnalyzer as SIA
sia = SIA()
results = []
for line in headlines:
pol_score = sia.polarity_scores(line)
pol_score['headline'] = line
results.append(pol_score)
pprint(results[:3], width=100)[{'compound': -0.5267,
'headline': 'DOJ watchdog reportedly sends criminal referral for McCabe to federal prosecutor',
'neg': 0.254,
'neu': 0.746,
'pos': 0.0},
{'compound': 0.0,
'headline': 'House Dems add five candidates to ‘Red to Blue’ program',
'neg': 0.0,
'neu': 1.0,
'pos': 0.0},
{'compound': 0.0,
'headline': 'DeveloperTown co-founder launches independent bid for U.S. Senate',
'neg': 0.0,
'neu': 1.0,
'pos': 0.0}]df = pd.DataFrame.from_records(results)
df.head()| compound | headline | neg | neu | pos | |
|---|---|---|---|---|---|
| 0 | -0.5267 | DOJ watchdog reportedly sends criminal referra... | 0.254 | 0.746 | 0.000 |
| 1 | 0.0000 | House Dems add five candidates to ‘Red to Blue... | 0.000 | 1.000 | 0.000 |
| 2 | 0.0000 | DeveloperTown co-founder launches independent ... | 0.000 | 1.000 | 0.000 |
| 3 | 0.5267 | Japanese PM Praises Trump for North Korea Brea... | 0.000 | 0.673 | 0.327 |
| 4 | 0.0000 | Democrats Back 'Impeach Trump' Candidates, Pol... | 0.000 | 1.000 | 0.000 |
Our dataframe consists of four columns from the sentiment scoring: Neu, Neg, Pos and compound. The first three represent the sentiment score percentage of each category in our headline, and the compound single number that scores the sentiment. `compound` ranges from -1 (Extremely Negative) to 1 (Extremely Positive).
We will consider posts with a compound value greater than 0.2 as positive and less than -0.2 as negative. There's some testing and experimentation that goes with choosing these ranges, and there is a trade-off to be made here. If you choose a higher value, you might get more compact results (less false positives and false negatives), but the size of the results will decrease significantly.
Let's create a positive label of 1 if the compound is greater than 0.2, and a label of -1 if compound is less than -0.2. Everything else will be 0.
df['label'] = 0
df.loc[df['compound'] > 0.2, 'label'] = 1
df.loc[df['compound'] < -0.2, 'label'] = -1
df.head()| compound | headline | neg | neu | pos | label | |
|---|---|---|---|---|---|---|
| 0 | -0.5267 | DOJ watchdog reportedly sends criminal referra... | 0.254 | 0.746 | 0.000 | -1 |
| 1 | 0.0000 | House Dems add five candidates to ‘Red to Blue... | 0.000 | 1.000 | 0.000 | 0 |
| 2 | 0.0000 | DeveloperTown co-founder launches independent ... | 0.000 | 1.000 | 0.000 | 0 |
| 3 | 0.5267 | Japanese PM Praises Trump for North Korea Brea... | 0.000 | 0.673 | 0.327 | 1 |
| 4 | 0.0000 | Democrats Back 'Impeach Trump' Candidates, Pol... | 0.000 | 1.000 | 0.000 | 0 |
We have all the data we need to save, so let's do that:
df2 = df[['headline', 'label']]
df2.to_csv('reddit_headlines_labels.csv', mode='a', encoding='utf-8', index=False)We can now keep appending to this csv, but just make sure that if you reassign the headlines set, you could get duplicates. Maybe add a more advanced saving function that reads and removes duplicates before saving.
Dataset Info and Statistics
Let's first take a peak at a few positive and negative headlines:
print("Positive headlines:\n")
pprint(list(df[df['label'] == 1].headline)[:5], width=200)
print("\nNegative headlines:\n")
pprint(list(df[df['label'] == -1].headline)[:5], width=200)Positive headlines:
['Japanese PM Praises Trump for North Korea Breakthrough',
"Bernie Sanders Joins Cory Booker's Marijuana Justice Act to Federally Legalize Weed",
'Trump Administration Seeks to Expand Sales of Armed Drones',
'AP: Trump leaves open possibility of bailing on meeting with Kim, Trump supported by Japan',
'Trump skews reasons behind his 2016 win']
Negative headlines:
['DOJ watchdog reportedly sends criminal referral for McCabe to federal prosecutor',
'Beyer Statement On Syria Strikes',
'Trump confidantes Bossie, Lewandowski urge against firing Mueller',
'Mattis disputes report he wanted Congress to approve Syria strike',
'Criminal charges recommended for fired FBI official Andrew McCabe']Now let's check how many total positives and negatives we have in this dataset:
print(df.label.value_counts())
print(df.label.value_counts(normalize=True) * 100)0 433
-1 332
1 200
Name: label, dtype: int64
0 44.870466
-1 34.404145
1 20.725389
Name: label, dtype: float64The first line gives us raw value counts of the labels, whereas the second line provides percentages with the normalize keyword.
For fun, let's plot a bar chart:
fig, ax = plt.subplots(figsize=(8, 8))
counts = df.label.value_counts(normalize=True) * 100
sns.barplot(x=counts.index, y=counts, ax=ax)
ax.set_xticklabels(['Negative', 'Neutral', 'Positive'])
ax.set_ylabel("Percentage")
plt.show()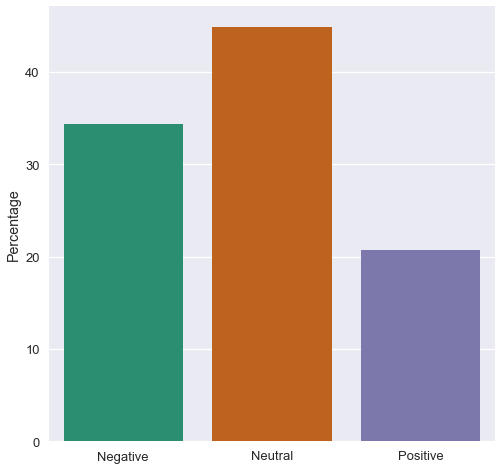
The large number of neutral headlines is due to two main reasons:
- The assumption that we made earlier where headlines with compound value between 0.2 and -0.2 are considered neutral. The higher the margin, the larger the number of neutral headlines.
- We used general lexicon to categorize political news. The more correct way is to use a political-specific lexicon, but for that we would either need a human to manually label data, or we would need to find a custom lexicon already made.
Another interesting observation is the number of negative headlines, which could be attributed to the media’s behavior, such as the exaggeration of titles for clickbait. Another possibility is that our analyzer produced a lot of false negatives.
There's definitely places to explore for improvements, but let's move on for now.
Tokenizers and Stopwords
Now that we gathered and labeled the data, let's talk about some of the basics of preprocessing data to help us get a clearer understanding of our dataset.
First of all, let’s talk about tokenizers. Tokenization is the process of breaking a stream of text up into meaningful elements called tokens. You can tokenize a paragraph into sentences, a sentence into words and so on.
In our case, we have headlines, which can be considered sentences, so we will use a word tokenizer:
from nltk.tokenize import word_tokenize, RegexpTokenizer
example = "This is an example sentence! However, it isn't a very informative one"
print(word_tokenize(example, language='english'))['This', 'is', 'an', 'example', 'sentence', '!', 'However', ',', 'it', 'is', "n't", 'a', 'very', 'informative', 'one']As you can see, the previous tokenizer, treats punctuation as words, but you might want to get rid of the punctuation to further normalize the data and reduce feature size. If that’s the case, you will need to either remove the punctuation, or use another tokenizer that only looks at words, such as this one:
tokenizer = RegexpTokenizer(r'\w+')
tokenizer.tokenize(example)['This', 'is', 'an', 'example', 'sentence', 'However', 'it', 'isn', 't', 'a', 'very', 'informative', 'one']There's quite a few tokenizers, and you can view them all here: http://www.nltk.org/api/nltk.tokenize.html. There's probably one that fits the bill more than others. The TweetTokenizer is a good example.
In the above tokens you'll also notice that we have a lot of words like ’the, ’is’, ’and’, ’what’, etc. that are somewhat irrelevant to text sentiment and don't provide any valuable information. These are called stopwords.
We can grab a simple list of stopwords from NLTK:
from nltk.corpus import stopwords
stop_words = stopwords.words('english')
print(stop_words[:20])['i', 'me', 'my', 'myself', 'we', 'our', 'ours', 'ourselves', 'you', 'your', 'yours', 'yourself', 'yourselves', 'he', 'him', 'his', 'himself', 'she', 'her', 'hers']This is a simple English stopword list that contains most of the common filler words that just add to our data size for no additional info. Further down the line, you'll most likely use a more advanced stopword list that's ideal for your use case, but NLTK's is a good start.
Word Distributions
Let's start by creating a function that will read a list of headlines and perform lowercasing, tokenizing, and stopword removal:
def process_text(headlines):
tokens = []
for line in headlines:
toks = tokenizer.tokenize(line)
toks = [t.lower() for t in toks if t.lower() not in stop_words]
tokens.extend(toks)
return tokensPositive Words
We can grab all of the positive label headlines from our dataframe, hand them over to our function, then call NLTK's `FreqDist` function to get the most common words in the positive headlines:
pos_lines = list(df[df.label == 1].headline)
pos_tokens = process_text(pos_lines)
pos_freq = nltk.FreqDist(pos_tokens)
pos_freq.most_common(20)[('trump', 80),
('says', 16),
('justice', 13),
('new', 13),
('senate', 12),
('york', 12),
('mueller', 11),
('comey', 11),
('support', 10),
('legal', 10),
('security', 9),
('white', 9),
('giuliani', 9),
('korea', 8),
('party', 8),
('donald', 8),
('cohen', 8),
('state', 8),
('like', 8),
('join', 8)]Now, let’s see the frequency of some of the tops words in the positive set:
Interestingly the most positive headline word is 'trump'!
Seeing that some of the other top positive words are having to do with with the Russia investigation, it's most likely the case that "trump" + "investigation news" is mostly seen as positive, but as we'll see in the negative word section, a lot of the same words appear so it's not definitive.
Let’s look at more macroscopic side by plotting the frequency distribution and try to examine the pattern of words and not each word specifically.
y_val = [x[1] for x in pos_freq.most_common()]
fig = plt.figure(figsize=(10,5))
plt.plot(y_val)
plt.xlabel("Words")
plt.ylabel("Frequency")
plt.title("Word Frequency Distribution (Positive)")
plt.show()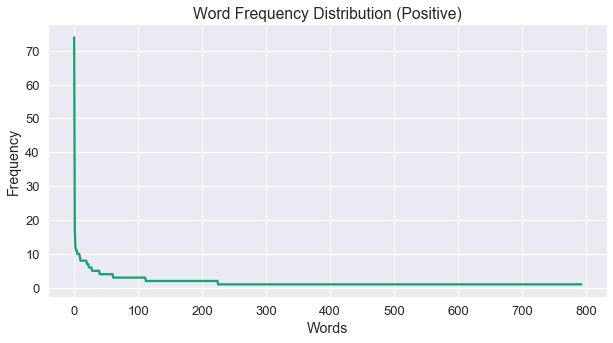
The above chart is showing the frequency patterns, where the y-axis is the frequency of the words and in x-axis is the words ranked by their frequency. So, the most frequent word, which in our case is ‘trump’, is plotted at $(1, 74)$.
For some of you, that plot may seem a bit familiar. That’s because it’s seems to be following the power-law distribution. So, to visually confirm it, we can use a log-log plot:
y_final = []
for i, k, z, t in zip(y_val[0::4], y_val[1::4], y_val[2::4], y_val[3::4]):
y_final.append(math.log(i + k + z + t))
x_val = [math.log(i + 1) for i in range(len(y_final))]
fig = plt.figure(figsize=(10,5))
plt.xlabel("Words (Log)")
plt.ylabel("Frequency (Log)")
plt.title("Word Frequency Distribution (Positive)")
plt.plot(x_val, y_final)
plt.show()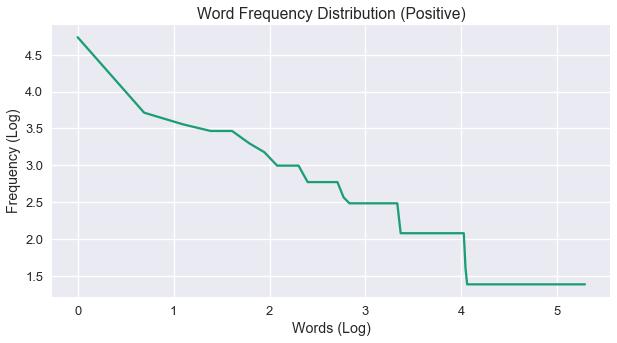
As expected, an almost straight line with a heavy tail (noisy tail). This shows that our data fits under the Zipf’s Law. In other words, the above plot shows that in our word distribution a vast minority of the words appear the most, while the majority of words appear less.
Negative Words
Now that we have examined the positive words, it’s time to shift towards the negative ones. Let's get and process the negative text data:
neg_lines = list(df2[df2.label == -1].headline)
neg_tokens = process_text(neg_lines)
neg_freq = nltk.FreqDist(neg_tokens)
neg_freq.most_common(20)[('trump', 125),
('mueller', 25),
('criminal', 21),
('judge', 20),
('mccabe', 19),
('court', 18),
('contempt', 17),
('police', 16),
('comey', 16),
('pittsburgh', 15),
('new', 15),
('kobach', 15),
('syria', 14),
('war', 14),
('senate', 13),
('u', 13),
('cohen', 13),
('case', 13),
('fires', 12),
('says', 12)]Well, the President does it again. He's also the top negative word. An interesting addition to the list are the words ‘syria’ and 'war'.
This post is being updated right when the first big strike on Syria occurred, so it seems pretty obvious why that would be seen as negative.
Interestingly, as noted above, we see some of the same words, like 'comey' and 'mueller', that appeared in the positive set. Some more analysis is needed to pin down the differences to see if we can separate more accurately, but for now let's move on to some of the plots for negative word distributions:
y_val = [x[1] for x in neg_freq.most_common()]
fig = plt.figure(figsize=(10,5))
plt.plot(y_val)
plt.xlabel("Words")
plt.ylabel("Frequency")
plt.title("Word Frequency Distribution (Negative)")
plt.show()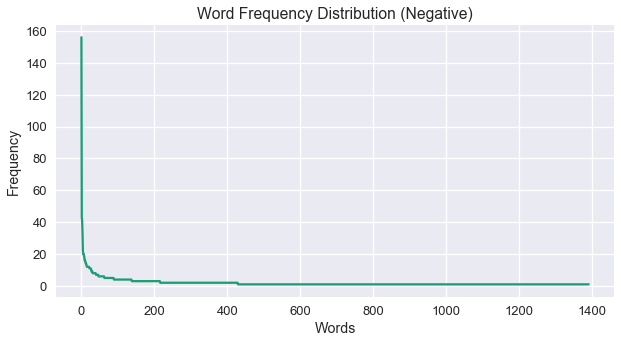
y_final = []
for i, k, z in zip(y_val[0::3], y_val[1::3], y_val[2::3]):
if i + k + z == 0:
break
y_final.append(math.log(i + k + z))
x_val = [math.log(i+1) for i in range(len(y_final))]
fig = plt.figure(figsize=(10,5))
plt.xlabel("Words (Log)")
plt.ylabel("Frequency (Log)")
plt.title("Word Frequency Distribution (Negative)")
plt.plot(x_val, y_final)
plt.show()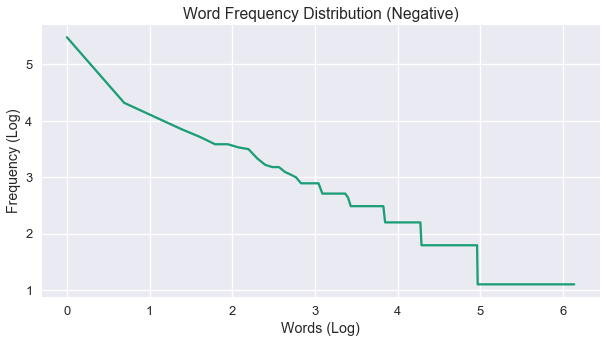
Negative distribution fits under the Zipf Law as well. A bit of more smooth slope, but the heavy tail is definitely there. The conclusion to be drawn here, is the exact same as the previous one shown in positive distribution.
Conclusion
As you can see, the Reddit API makes it extremely easy to compile a lot of news data fairly quickly. It's definitely worth the time and effort to enhance the data collection steps since it's so simple to get thousands of rows of political headlines to use for further analysis and prediction.
There's still a lot that could be engineered in regards to data mining, and there's still a lot to do with the data retrieved. The the next tutorial we will continue our analysis by the dataset to construct and train a sentiment classifier.
Meet the Authors


LearnDataSci Author, postgraduate in Computer Science & Engineering at the University Ioannina, Greece, and Computer Science undergraduate teaching assistant.